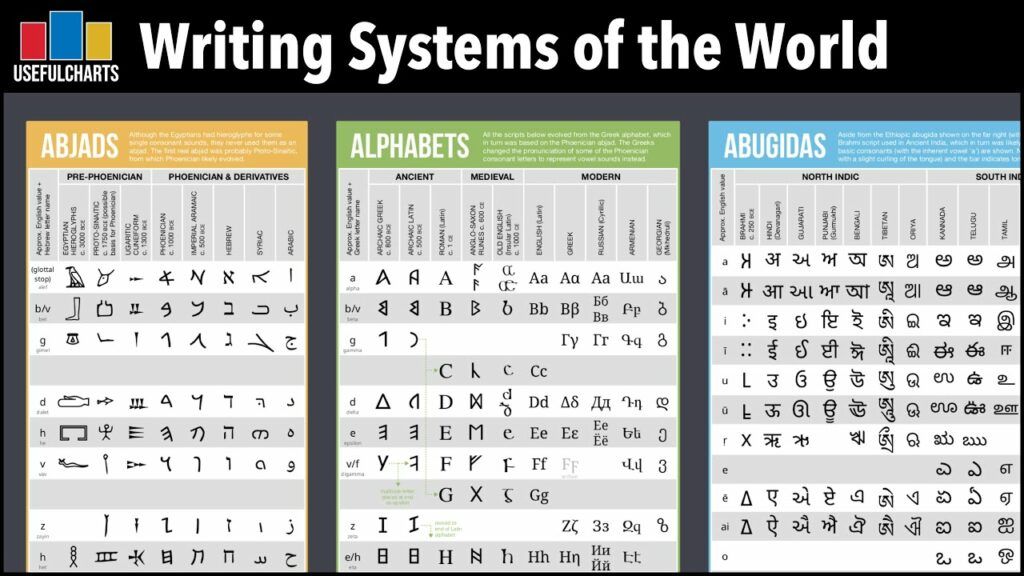
Human languages are primarily spoken, but the systems humans have invented to record speech in visible form are astonishingly varied. A literate adult in Madrid, Moscow, Cairo, Beijing, and Tokyo all read using fundamentally different principles of mapping sound to symbol. This reference compares the four major script families in use today - alphabets, abjads, abugidas, and syllabaries - along with the mixed logographic systems of East Asia. It examines how each type encodes the spoken language, why each emerged historically, how many symbols a learner must master, and how difficult each is to acquire for a native speaker of English.
The aim here is classification and comparison, not advocacy. No writing system is objectively "better" than another. Each developed in response to the phonological structure of the language it was designed to record, and each carries historical, aesthetic, and cultural weight that far exceeds its strict functional load. However, for a learner approaching a new language, understanding which category its script belongs to - and how that category works - dramatically reduces the time needed to begin reading.
Throughout this article, native script examples appear in their original form. The reader is expected to encounter Cyrillic, Arabic, Chinese, Japanese hiragana, Japanese katakana, Japanese kanji, and Spanish diacritics as representative samples. Do not worry if a script is unfamiliar. Each will be introduced and compared against the others on concrete criteria: symbol count, symbol-sound ratio, writing direction, and cognitive load for a Latin-script reader.
What Is a Writing System
A writing system is a conventional set of visible signs used to represent linguistic units. The linguistic unit represented is the defining variable. In an alphabet, the symbol represents a phoneme (a single consonant or vowel). In an abjad, the symbol represents a consonant, and vowels are usually omitted or added as optional diacritics. In an abugida, the symbol is a consonant that carries an inherent vowel, modifiable by diacritics. In a syllabary, the symbol represents a whole syllable (typically consonant plus vowel). In a logography, the symbol represents a morpheme - a unit of meaning, often a whole word.
Table 1: The Five Main Script Types
| Type | Unit Represented | Symbol Count (typical) | Example Scripts | Example Language |
|---|---|---|---|---|
| Alphabet | Phoneme (consonant or vowel) | 20-40 | Latin, Cyrillic, Greek | English, Russian, Greek |
| Abjad | Consonant only | 22-28 | Arabic, Hebrew | Arabic, Hebrew |
| Abugida | Consonant with inherent vowel | 30-50 base, plus vowel marks | Devanagari, Ge'ez | Hindi, Amharic |
| Syllabary | Syllable | 40-100+ | Hiragana, Katakana | Japanese |
| Logography | Morpheme (meaning unit) | Thousands | Hanzi, Kanji | Chinese, Japanese |
In practice these categories are not airtight. Modern Arabic adds diacritics when teaching children or printing the Quran, effectively becoming an abugida in those contexts. Japanese mixes a syllabary (hiragana), a second syllabary (katakana), and a logography (kanji) in nearly every sentence. English orthography, although alphabetic, is so deeply etymological that the same letter sequence often represents different sounds ("ough" in "though," "through," "tough," "cough"). The categories are a guide, not a straitjacket.
Alphabets: Latin, Cyrillic, and Greek
An alphabet assigns one symbol (ideally) to one phoneme. Both consonants and vowels receive their own letters. This is the most phonologically transparent of the major script types and, partly for this reason, it has spread more widely than any other. Alphabets include the Latin script used for English, Spanish, French, German, Vietnamese, Turkish, and hundreds of other languages; the Cyrillic script used for Russian, Ukrainian, Bulgarian, Serbian, and dozens of Central Asian languages; and the Greek alphabet, from which Latin and Cyrillic both descend.
Table 2: Major Alphabetic Scripts Compared
| Script | Letters | Origin | Date | Modern Users |
|---|---|---|---|---|
| Latin | 26 (English); up to 30+ with diacritics | Etruscan from Greek | c. 700 BCE | Most of Europe, Americas, much of Africa, Southeast Asia |
| Cyrillic | 33 (Russian) | Adapted from Greek uncial | 9th century CE | Russia, Ukraine, Belarus, Bulgaria, Serbia, Central Asia |
| Greek | 24 | Phoenician | c. 800 BCE | Greece, Cyprus |
The shared ancestry shows: A, B, E, K, M, O, T appear in all three in recognizable form. Cyrillic looks unfamiliar mostly because some letters take unexpected values. For example, Cyrillic B sounds like English V, P sounds like R, H sounds like N, and X sounds like the "ch" in German "Bach." A dedicated reader can achieve fluent decoding of Cyrillic in one to three weeks. See the Russian Cyrillic alphabet reference for the complete letter-by-letter walkthrough.
Spanish uses the Latin alphabet with one additional letter, ñ, plus accent marks (á, é, í, ó, ú) that mark stress rather than vowel quality. The orthography is nearly phonemic - meaning how a word is written almost perfectly predicts how it is pronounced - which makes Spanish reading far easier than English reading once the basic rules are learned. See the Spanish alphabet and pronunciation guide for full details on ñ, the h (silent), and the two different pronunciations of c and g.
Consistency of sound-to-symbol mapping varies wildly even within the alphabet category. Finnish, Turkish, and Spanish are nearly one-to-one. English is notoriously irregular, with the same letter representing many sounds and the same sound represented by many letters. Russian is mostly phonemic but has stress-dependent vowel reduction (the letter o is pronounced /o/ when stressed and approaches /a/ when unstressed), as explained in the Russian pronunciation and stress guide.
Abjads: Arabic and Hebrew
An abjad is a consonant-primary script. Vowels are traditionally unwritten, or written only as supplementary marks. The reader reconstructs vowels from context, lexical knowledge, and grammatical pattern recognition. To a beginner this sounds impossible, but in practice Semitic languages like Arabic and Hebrew have root-and-pattern morphology: most words are built from a three-consonant root (for example k-t-b "to write") plugged into vocalic patterns that signal grammatical role. Once a reader knows the patterns, the consonants alone are usually sufficient to disambiguate the word.
Arabic has 28 letters, written right to left. Each letter changes form depending on whether it appears at the beginning, middle, or end of a word, or stands alone. A single letter may therefore have four distinct shapes, all of which the reader must recognize. The sentence "I wrote the book" is roughly كَتَبْتُ الْكِتَابَ (katabtu al-kitaba), but in ordinary running text the short-vowel diacritics are omitted and it appears as كتبت الكتاب.
Table 3: Arabic Letter Shape Variants
| Letter Name | Isolated | Initial | Medial | Final |
|---|---|---|---|---|
| baa | ب | بـ | ـبـ | ـب |
| taa | ت | تـ | ـتـ | ـت |
| meem | م | مـ | ـمـ | ـم |
| noon | ن | نـ | ـنـ | ـن |
Hebrew has 22 letters, also written right to left, without the positional shape variants of Arabic. Children's books and religious texts add vowel points (niqqud), but standard Hebrew newspapers and novels omit them. The Bible is traditionally pointed to preserve liturgical pronunciation.
A full introduction to Arabic letter forms, positional variants, and connection rules is available in the Arabic alphabet complete guide for beginners. For pronunciation-level detail on how the letters actually sound, including the pharyngeal and emphatic consonants that have no English parallels, see the Arabic pronunciation guide for English speakers.
Abugidas: Devanagari and Ge'ez
Between alphabets and abjads lies a third system: the abugida, sometimes called an alphasyllabary. Here each consonant symbol carries an inherent default vowel (usually short "a"), and other vowels are indicated by diacritics attached to the consonant. Devanagari (used for Hindi, Sanskrit, Marathi, Nepali) is the most widely read abugida. Ge'ez script is used for Amharic and Tigrinya in Ethiopia and Eritrea. Thai, Khmer, Tibetan, and many Indian scripts are also abugidas.
Because abugidas are less relevant to the five reference languages this series focuses on, they receive only a brief note here. The crucial distinction for our comparisons is that abugidas write vowels explicitly (unlike abjads) but fuse them to consonants (unlike alphabets). The number of base symbols tends to run higher than in an alphabet and lower than in a syllabary.
Syllabaries: Japanese Hiragana and Katakana
A syllabary assigns one symbol to one whole syllable. Japanese hiragana and katakana each have 46 base symbols representing the syllables of Japanese (a, i, u, e, o, ka, ki, ku, ke, ko, sa, shi, su, se, so, and so on). With diacritics and small-y combinations, the total of distinct graphemes reaches roughly 100 per script.
Table 4: Hiragana Gojuuon (First Three Rows)
| Vowel | a | i | u | e | o |
|---|---|---|---|---|---|
| (vowels) | あ | い | う | え | お |
| k- | か | き | く | け | こ |
| s- | さ | し | す | せ | そ |
Table 5: Katakana (Same Syllables)
| Vowel | a | i | u | e | o |
|---|---|---|---|---|---|
| (vowels) | ア | イ | ウ | エ | オ |
| k- | カ | キ | ク | ケ | コ |
| s- | サ | シ | ス | セ | ソ |
Hiragana handles native Japanese words, grammatical endings, and particles. Katakana handles loanwords from other languages (especially English), onomatopoeia, and emphasis. They are parallel systems. Every syllable writable in hiragana has a katakana equivalent. The word "coffee" is written コーヒー (koohii) in katakana because it is borrowed from Dutch/English. The grammatical particle は (wa) is always written in hiragana. See the Japanese hiragana complete guide for the full chart and stroke orders, and the katakana complete guide for the parallel system and its use cases.
Because Japanese phonology is simple - most syllables are just consonant plus vowel, with a small total inventory - a syllabary fits it efficiently. A syllabary would be impractical for English, which has thousands of possible syllable shapes due to complex consonant clusters (strengths is one syllable).
Logographies: Chinese Hanzi and Japanese Kanji
A logography uses one symbol to represent one morpheme - a unit of meaning rather than a unit of sound. Chinese characters (hanzi in Chinese, kanji in Japanese) are the most widely used logographic system. There are roughly 50,000 hanzi in the most comprehensive dictionaries, though basic literacy in modern Chinese requires about 3,000 to 3,500 characters and educated adults know 5,000 to 8,000.
Each character represents one morpheme and (in Chinese) one syllable. The character 水 means "water" and is pronounced shuǐ. The character 山 means "mountain" and is pronounced shān. The character 人 means "person" and is pronounced rén.
Many characters are built from simpler components called radicals, which suggest meaning and sometimes sound. For example, the character 湖 (lake) contains the water radical 氵on the left and the phonetic component 胡 (hú) on the right. A reader who knows both components can often guess both meaning category and pronunciation of an unknown character. See the Chinese characters and radicals guide for how radicals organize the writing system.
Table 6: Sample Characters, Meaning, and Pronunciation
| Character | Meaning | Mandarin Pinyin | Japanese On'yomi | Japanese Kun'yomi |
|---|---|---|---|---|
| 水 | water | shuǐ | sui | mizu |
| 山 | mountain | shān | san | yama |
| 人 | person | rén | jin | hito |
| 日 | sun/day | rì | nichi/jitsu | hi |
| 月 | moon/month | yuè | getsu | tsuki |
| 火 | fire | huǒ | ka | hi |
Japanese kanji are borrowed from Chinese hanzi and preserve the characters' meanings, but in Japanese each character has multiple readings: the on'yomi (Sino-Japanese reading, borrowed approximately from Middle Chinese) and the kun'yomi (native Japanese reading). Which reading applies depends on context and compound. This is one reason Japanese literacy takes so long: a reader must master not only the 2,000 to 3,000 characters of ordinary life but also the conventions that select one reading over another in each compound word.
Chinese also uses tones to distinguish syllables. The syllable "ma" in Mandarin can mean mother (mā, high level), hemp (má, rising), horse (mǎ, falling-rising), or scold (mà, falling). For an introduction to these tonal distinctions, see the Chinese tones complete guide. For the romanization system that allows Chinese to be written phonetically with Latin letters, see the pinyin complete guide.
Mixed Systems: Japanese's Three-Script Integration
Japanese is remarkable in using three scripts simultaneously, each with a distinct functional role. A single modern Japanese sentence almost always contains all three.
Consider: 私は本を読みます (watashi wa hon wo yomimasu) - "I read a book."
- 私 (watashi) - kanji, meaning "I"
- は (wa) - hiragana, topic-marking particle
- 本 (hon) - kanji, meaning "book"
- を (wo) - hiragana, direct-object particle
- 読み (yomi) - kanji plus hiragana, the verb stem "read" plus its inflection
- ます (masu) - hiragana, polite ending
Katakana would appear for a loanword (for example, コンピューター for "computer") or an onomatopoeia. The practical effect is that every Japanese sentence is a miniature typographic composition: readers use the script change itself as a visual cue for where one word ends and the next begins - a function that Japanese space-less writing otherwise lacks. See the Japanese grammar particles complete guide for how the hiragana particles structure the grammar.
Writing Direction
Most writing systems in current use write left to right (LTR). Arabic and Hebrew write right to left (RTL). Traditional Chinese and Japanese were written top to bottom (TTB), in columns running right to left across the page, and this vertical format is still common in novels, manga, and formal calligraphy, although modern prose and digital text overwhelmingly use LTR horizontal.
Table 7: Writing Direction by Script
| Direction | Scripts |
|---|---|
| Left to right | Latin, Cyrillic, Greek, Devanagari, modern Chinese and Japanese |
| Right to left | Arabic, Hebrew, Syriac |
| Top to bottom, columns right-to-left | Traditional Chinese, Japanese, Mongolian (rotated) |
| Boustrophedon (alternating) | Ancient Greek (historical) |
Within an RTL text, certain elements switch direction. Numbers in Arabic are written left to right even though surrounding text runs right to left. Software must handle bidirectional text, which is why early computer support for Arabic and Hebrew lagged behind LTR languages.
Historical Development
The ancestor of most modern alphabets and abjads is the Phoenician script, which emerged in the eastern Mediterranean around 1050 BCE. Phoenician was itself an abjad (consonants only). Phoenician traders spread the script across the Mediterranean; the Greeks borrowed it, added vowel signs for sounds that did not exist in Phoenician, and thereby produced the first true alphabet around 800 BCE. From Greek came Latin (via Etruscan) and Cyrillic (via Old Church Slavonic, adapted in the 9th century by saints Cyril and Methodius for missionary work among the Slavs).
Arabic and Hebrew also descend from the Phoenician branch, through Aramaic intermediaries, preserving the consonant-only abjad principle. Chinese characters developed independently, emerging in oracle bone inscriptions around 1200 BCE, and have evolved continuously ever since. Japanese kanji are direct borrowings from Chinese hanzi, imported along with Buddhist texts starting in the 5th century CE. Hiragana and katakana were both derived from simplified cursive and angular forms of certain kanji, developed in Japan between the 8th and 10th centuries.
Table 8: Approximate Ancestry of Major Scripts
| Modern Script | Parent | Approximate Date Borrowed |
|---|---|---|
| Greek | Phoenician | c. 800 BCE |
| Latin | Etruscan from Greek | c. 700 BCE |
| Cyrillic | Greek uncial | 9th century CE |
| Arabic | Nabataean from Aramaic | 4th century CE |
| Hebrew (square) | Aramaic | 3rd century BCE |
| Hanzi | Oracle bone script (independent) | c. 1200 BCE |
| Kanji | Hanzi | 5th century CE |
| Hiragana | Kanji cursive | 8-9th century CE |
| Katakana | Kanji fragments | 9th century CE |
Difficulty for English Native Speakers
Writing system distance is a significant factor in overall language-learning difficulty, but it is far from the only one. A learner of French faces minimal script difficulty but still must acquire French phonology and grammar. A learner of Russian faces a modest script barrier (a few weeks) but a substantial grammar barrier (years). A learner of Chinese faces a writing-system barrier that never fully goes away - educated adult Chinese native speakers continue to encounter unfamiliar characters their entire lives - layered on top of tonal phonology and an entirely different grammar.
Table 9: Time to Basic Reading Fluency for an English-Native Adult, by Script
| Script | Approximate Time to Basic Reading | Bottleneck |
|---|---|---|
| Latin (Spanish/French/German) | Hours to days | Orthography rules |
| Cyrillic | 1-3 weeks | Letter-sound remapping |
| Greek | 1-3 weeks | Similar to Cyrillic |
| Arabic script | 2-4 weeks | Positional forms, RTL, no vowels in running text |
| Hebrew | 2-4 weeks | RTL, no vowels in running text |
| Hiragana | 2-4 weeks | New symbols but fully phonetic |
| Katakana | 2-4 weeks | Same learning curve as hiragana |
| Hanzi/Kanji | Years | Character-by-character; 2000+ for basic literacy |
Note that the hiragana and katakana estimates assume a learner studies only one at a time, roughly one week each. Learning kanji on top of the two syllabaries is the real time sink of Japanese literacy and typically continues for the entire duration of serious study.
Sample Word: "Book" Across Writing Systems
A single concrete example shows how wildly differently the same concept is encoded. The word for "book" in each language is written as follows:
Table 10: "Book" in Nine Scripts
| Language | Script | Native Form | Romanization |
|---|---|---|---|
| English | Latin | book | book |
| Spanish | Latin + diacritics | libro | libro |
| German | Latin | Buch | Buch |
| Russian | Cyrillic | книга | kniga |
| Greek | Greek | βιβλίο | vivlio |
| Arabic | Arabic | كتاب | kitab |
| Hebrew | Hebrew | ספר | sefer |
| Mandarin | Hanzi | 书 (simplified), 書 (traditional) | shū |
| Japanese | Kanji | 本 | hon |
Same concept, nine encodings, three fundamentally different principles (alphabetic, consonantal, logographic), three writing directions in ordinary use. No visual clue would connect any of these forms without knowing the language.
Summary Comparison Table
Table 11: Five Writing System Types at a Glance
| Feature | Alphabet | Abjad | Abugida | Syllabary | Logography |
|---|---|---|---|---|---|
| Unit | Phoneme | Consonant | Consonant + inherent vowel | Syllable | Morpheme |
| Vowels explicit | Yes | No (optional diacritics) | Yes (diacritics) | Yes (fused) | N/A |
| Symbol count | 20-40 | 22-28 | 30-50 base | 40-100+ | 3,000+ for literacy |
| Fit for simple syllable structure | Good | Good | Good | Excellent | Any |
| Fit for complex syllable structure | Excellent | Adequate | Good | Poor | Any |
| Cognitive load on learner | Low | Medium | Medium | Medium | High |
| Examples | Latin, Cyrillic, Greek | Arabic, Hebrew | Devanagari | Hiragana, Katakana | Hanzi, Kanji |
FAQ
Q: What is the oldest writing system still in use? A: Chinese characters, in continuous use since around 1200 BCE. The Phoenician-Greek-Latin line is of comparable age as a tradition, but no individual modern letter form is as close to its 3,000-year-old ancestor as many Chinese characters are.
Q: Why do Japanese writers need three scripts? A: Each script has a functional role. Hiragana writes native grammatical endings, particles, and words lacking common kanji. Katakana marks foreign borrowings, onomatopoeia, and emphasis. Kanji carries the core lexical meaning of nouns and verb stems. Because Japanese text lacks word spaces, the script switching itself helps readers segment words.
Q: Are abjads really readable without vowels? A: Yes, for fluent readers of Semitic languages. The root-and-pattern morphology of Arabic and Hebrew makes most words reconstructable from their consonants plus context. Beginners and children's books add vowel marks; general adult reading omits them.
Q: How many Chinese characters do I need to know for basic reading? A: Around 1,000 characters covers most common contexts at a beginner level. 2,000 to 2,500 covers most newspaper text. 3,500 to 5,000 is typical for educated readers. The PRC Table of General Standard Chinese Characters contains 8,105 characters for reference.
Q: Is Russian harder to read than Arabic? A: No. For most English speakers, Cyrillic is faster to learn than Arabic script because Cyrillic has fixed letter shapes and reads left to right. Arabic adds positional shape variation, right-to-left direction, and the omission of short vowels in running text.
Q: Why is English spelling so irregular if it is alphabetic? A: English orthography reflects the pronunciations of many historical stages and source languages (Old English, Norse, French, Latin, Greek) that were standardized in print before the sound changes of Early Modern English had completed. The result is an orthography that signals etymology as much as phonology.
Q: Will Chinese switch to an alphabet? A: It is very unlikely. The pinyin system provides a phonetic auxiliary used for teaching and input, but Chinese readers show no sign of abandoning characters. Characters allow readers of different regional varieties of Chinese to read the same text, which a phonetic script would not permit without standardization on one variety.
See Also
- Russian Cyrillic alphabet complete guide
- Russian pronunciation and stress guide
- Arabic alphabet complete guide for beginners
- Arabic pronunciation guide for English speakers
- Chinese characters and radicals guide
- Chinese tones complete guide with examples
- Pinyin complete guide to Chinese pronunciation
- Japanese hiragana complete guide
- Japanese katakana complete guide
- Japanese grammar particles complete guide
- Spanish alphabet and pronunciation guide
- Spanish grammar rules complete beginners guide
Frequently Asked Questions
What is the oldest writing system still in use?
Chinese characters, in continuous use since around 1200 BCE. The Phoenician-Greek-Latin line is of comparable age as a tradition, but no individual modern letter form is as close to its 3,000-year-old ancestor as many Chinese characters are.
Why do Japanese writers need three scripts?
Each script has a functional role. Hiragana writes native grammatical endings and particles. Katakana marks foreign borrowings, onomatopoeia, and emphasis. Kanji carries the core lexical meaning of nouns and verb stems. Because Japanese text lacks word spaces, the script switching itself helps readers segment words.
Are abjads really readable without vowels?
Yes, for fluent readers of Semitic languages. The root-and-pattern morphology of Arabic and Hebrew makes most words reconstructable from their consonants plus context. Beginners and children’s books add vowel marks; general adult reading omits them.
How many Chinese characters do I need to know for basic reading?
Around 1,000 characters covers most common contexts at a beginner level. 2,000 to 2,500 covers most newspaper text. 3,500 to 5,000 is typical for educated readers.
Is Russian harder to read than Arabic?
No. For most English speakers, Cyrillic is faster to learn than Arabic script because Cyrillic has fixed letter shapes and reads left to right, while Arabic adds positional shape variation, right-to-left direction, and the omission of short vowels in running text.
Why is English spelling so irregular if it is alphabetic?
English orthography reflects the pronunciations of many historical stages and source languages (Old English, Norse, French, Latin, Greek) that were standardized in print before the sound changes of Early Modern English completed. The result signals etymology as much as phonology.
Will Chinese switch to an alphabet?
It is very unlikely. The pinyin system provides a phonetic auxiliary used for teaching and input, but characters allow readers of different regional varieties of Chinese to read the same text, which a phonetic script would not permit without standardization on one variety.